Database Architecture Interview questions
 Overview
Overview
This is an interesting topic and yes it’s the most discussed one when it comes to SQL Server interviews.
In SQL Server interviews database design conversation goes in to two wide discussions one is Normalization and the other is de-normalization.
So in normalization section interviewer can ask you questions around the 3 normal forms i.e. 1st normal form, second normal form and 3rd normal form. This looks to be a very simple question but you would be surprised to know even veteran database designers forget the definition thus giving an impression to the interviewer that they do not know database designing.
Irrespective you are senior or a junior everyone expects you to answer all the 3 normal forms. There are exceptions as well where interviewer has asked about 4th and 5th normal form as well but you can excuse those if you wish. I personally think that’s too much to ask for.
When it comes to database designing technique interviewer can query the other side of the coin i.e. de-normalization. One of the important questions which interviewers can query is around Difference between de-normalization and normalization. The expectation from most of the interviewers when answering the differences is from the perspective of performance and type of application.
As people discuss ahead there is high possibility of getting in to OLTP and OLAP discussions which can further trigger discussions around database designing techniques Star and Snow flake schema.
 See the following video on SQL server interview question: - Difference between unique and primary keys?
See the following video on SQL server interview question: - Difference between unique and primary keys?
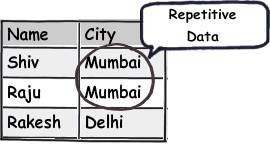
It’s a database design technique to avoid repetitive data and maintain integrity of the data.
Note: - After that sweet one line, I can bet the interviewer will ask you to clarify more on those two words repetitive and integrity word.
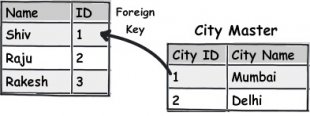
Let’s first start with repetitive. Let’s say you have a simple table of user as shown below. You can see how the city is repeated again and again. So you would like to improve on this.
So to solve the problem, very simple you apply normalization. You split that repetitive data in to separate table (city master) and put a reference foreign key as shown in the below figure.
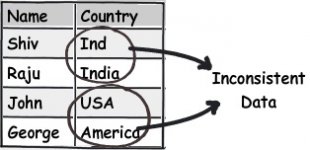
Now the second word “Data integrity”. “Data integrity” means how much accurate and consistent your data is.
For instance in the below figure you can see how the name of the country is inconsistent. “Ind” and “India” means the same thing, “USA” and “United States” means the same the thing. This kind of inconsistency leads to more complication and problems in maintenance.
One of the most important thing in technical interviews like SQL.NET, Java etc is that you need to use proper technical vocabulary. For example in the above answer the word “Data integrity” attracts the interviewer than the word “Inaccurate”. Right technical vocabulary will make you shine as compared to people who use plain English.
See the following video on SQL server interview question: - Difference between Union and Union All?
Its surprising that many experienced professionals cannot answer this question. So below is simplified one liner’s for each of these normal forms.- First normal form is all about breaking data in to smaller logical pieces.
- In Second normal form all column data should depend fully on the key and not partially.
- In Third normal form no column should depend on other columns.
For in-depth explanation you can also see the video :- Can you explain First, Second & Third Normal forms in database? provided in the DVD.
Denormalization is exact opposite of normalization. Normalization is good when we want to ensure that we do not have duplicate and inconsistent data. In other words when we want to do operational activities like insert, update, delete and simple reports normalization design is perfectly suited. Putting in other words when data comes in to the system a normalized design would be the best suited.
But what if the we want to analyze historical data, do forecasting, do heavy calculations etc. For these kinds of requirements normalization design is not suited. Forecasting and analyzing are heavy operations and with historical data it becomes heavier. If your design is following normalization then your SQL needs to pull from different tables making the select process slow.
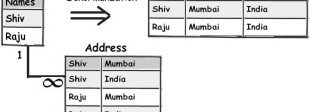
Normalization is all about reducing redundancy while denormalization is all about increasing redundancy and minimizing number of tables.
In the above figure you can see at the left hand side we have a normalized design while in the right hand side we have denormalized design. A query on the right side denormalized table will be faster as compared to the left hand side because there are more tables involved.
You will use denormalized design when your application is more meant to do reporting, forecasting and analyzing historical data where read performance is more important.
See the following SQL Server interview question video on Difference between subquery and co-related queries ?
Both OLTP and OLAP are types of IT systems.OLTP (Online transaction processing system) deals with transactions ( insert, update, delete and simple search ) while OLAP (Online analytical processing) deals with analyzing historical data, forecasting etc.

Share this article
Related Posts


Latest Posts